leader选举
状态转移
启动时都是follower状态。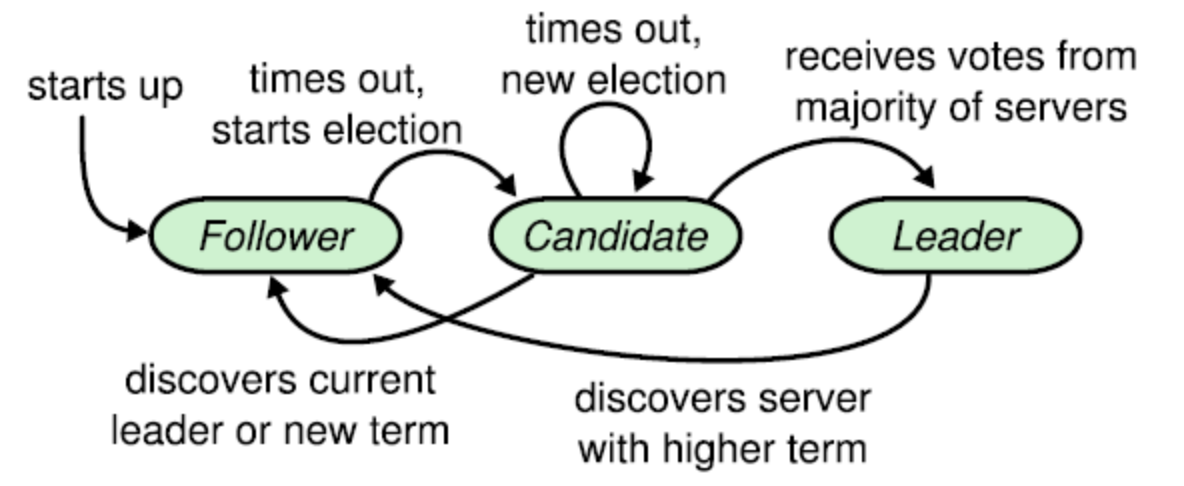
timeout
election
时间在150ms到300ms之间随机选取,如果到期没有发现leader的心跳出现,就把自己的状态转换为candidate,给自己投一票,并且请求其他结点开始投票。如果接受到请求的结点在这个任期内没有投过票,就给候选人投票,并且把自己的election timeout重置。
一旦候选人得到大部分票选,就成为leader。
heartbeat
leader以心跳周期给followers发送Append entry,直到出现新的term的leader,回到follower状态。
如果follower在election timeout内没有收到心跳,以候选人开启新的term,选出新的leader。
任期
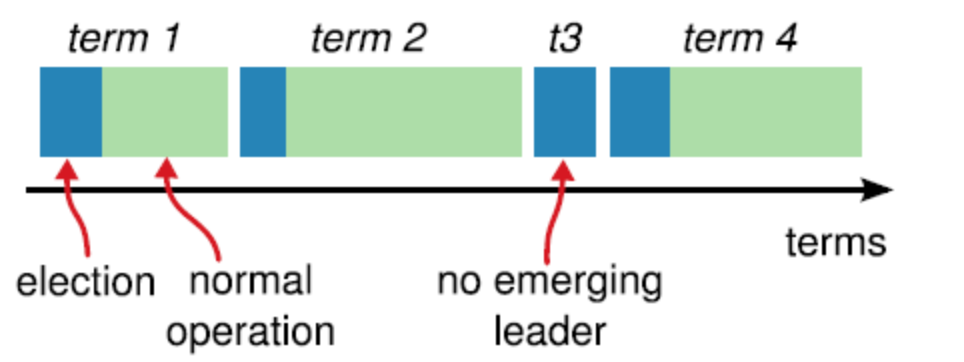
term(任期)以选举(election)开始,然后就是一段或长或短的稳定工作期(normal Operation)。从上图可以看到,任期是递增的,这就充当了逻辑时钟的作用;另外,term 3 展示了一种情况,就是说没有选举出 leader 就结束了,然后会发起新的选举,这是平票 split vote 的情况。
split vote
同时有多个候选人,得到了相同票数,无法选出leader。等待超时,重新发起投票。
log replication
复制状态机
相同的初识状态 + 相同的输入 = 相同的结束状态。
在 raft 中,leader 将客户端请求(command)封装到一个个 log entry,将这些 log entries 复制(replicate)到所有 follower 节点,然后大家按相同顺序应用(apply)log entry 中的 command,则状态肯定是一致的。
请求完整流程
当系统(leader)收到一个来自客户端的写请求,到返回给客户端,整个过程从 leader 的视角来看会经历以下步骤:
- leader append log entry
- leader issue AppendEntries RPC in parallel
- leader wait for majority response
- leader apply entry to state machine
- leader reply to client
- leader notify follower apply log
安全
选举安全
在 raft 中,两点保证了这个属性:
- 一个节点某一任期内最多只能投一票;
- 只有获得 majority 投票的节点才会成为 leader。
任一任期内最多一个 leader 被选出。
log 匹配
如果两个节点上的某个 log entry 的 log index 相同且 term 相同,那么在该 index 之前的所有 log entry 应该都是相同的。
首先,leader 在某一 term 的任一位置只会创建一个 log entry,且 log entry 是 append-only。其次,consistency check。leader 在 AppendEntries 中包含最新 log entry 之前的一个 log 的 term 和 index,如果 follower 在对应的 term index 找不到日志,那么就会告知 leader 不一致。
当出现了 leader 与 follower 不一致的情况,leader 强制 follower 复制自己的 log。
- leader 初始化 nextIndex[x] 为 leader 最后一个 log index + 1
- AppendEntries 里 prevLogTerm prevLogIndex 来自 logs[nextIndex[x] - 1]
- 如果 follower 判断 prevLogIndex 位置的 log term 不等于 prevLogTerm,那么返回 False,否则返回 True
- leader 收到 follower 的回复,如果返回值是 False,则 nextIndex[x] -= 1, 跳转到 第2步.
- 否则,同步 nextIndex[x] 后的所有 log entries
leader完整性
leader 完整性:如果一个 log entry 在某个任期被提交(committed),那么这条日志一定会出现在所有更高 term 的 leader 的日志里面。
raft 与其他协议(Viewstamped Replication、mongodb)不同,raft 始终保证 leader 包含最新的已提交的日志,因此 leader 不会从 follower catchup 日志,这也大大简化了系统的复杂度。
边界条件
旧leader
raft 保证 Election safety,即一个任期内最多只有一个 leader,但在网络分割(network partition)的情况下,可能会出现两个 leader,但两个 leader 所处的任期是不同的。
leader 如果收不到 majority 节点的消息,那么无法进行commit。如果网络恢复了,发现有更高term的leader,会转换到follower,并且把没有commit的entry回滚,同步到新的leader。
状态机安全
如果节点将某一位置的 log entry 应用到了状态机,那么其他节点在同一位置不能应用不同的日志。简单点来说,所有节点在同一位置(index in log entries)应该应用同样的日志。
某个 leader 选举成功之后,不会直接提交前任 leader 时期的日志,而是通过提交当前任期的日志的时候 “顺手” 把之前的日志也提交了,具体怎么实现了,在 log matching 部分有详细介绍。那么问题来了,如果 leader 被选举后没有收到客户端的请求呢,论文中有提到,在任期开始的时候发立即尝试复制、提交一条空的 log。
leader crash
为了避免问题的设计
- 避免平票:randomized election timeouts ;
- 保证majority票:节点的数目都是奇数个;
- 保证高可用:不是强一致性,而是最终一致性,leader 会不断尝试给 follower 发 log entries,直到所有节点的 log entries 都相同;
容错数量
raft 算法只支持容错故障节点,假设集群总节点数为n,故障节点为 f ,根据小数服从多数的原则,集群里正常节点只需要比 f 个节点再多一个节点,即 f+1 个节点,正确节点的数量就会比故障节点数量多,那么集群就能达成共识。因此 raft 算法支持的最大容错节点数量是(n-1)/2。
